


4000-690-986


从实用高效的集群到超级计算机,我们广泛的高性能服务器和存储产品阵容使我们能够创建独特的配置来应对任何弹性工作负载。
星宏伟业官方代理的supermicro正在积极创新HPC解决方案。从设计到实施,我们优化每个解决方案的每个方面。我们的优势包括各种构建模块,从主板设计到系统配置,再到完全集成的机架和液体冷却系统。使用这些大量的多功能构建模块,我们专注于根据客户需求提供量身定制的解决方案。
星宏伟业可以定制HPC解决方案以满足各种工作负载:不同行业中使用的计算密集型,高吞吐量或高容量存储应用程序。Supermicro HPC系统可与各种开源平台和商业应用捆绑在一起,使其成为真正的交钥匙解决方案。
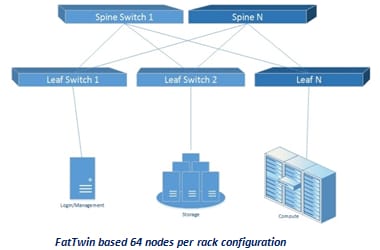
HPC RA利用Supermicro的高密度FatTwin服务器以及Fat Tree拓扑中的Supermicro Omni-Path交换机。这种设计可以实现Petaflops的计算能力,并且与大存储库一起,它可以承担最苛刻的HPC任务。高级FatTwin系统提供高密度计算性能,存储容量和功率效率。

计算能力:
网络:
冷却:
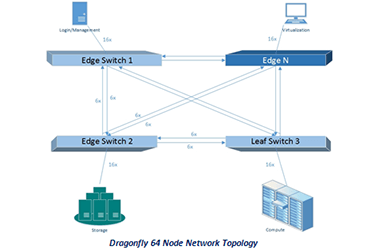
该设计利用TwinPro的速度和效率以及蜻蜓拓扑中的Mellanox Infiniband网络。蜻蜓拓扑最小化网络直径并最大化带宽,从而可以在顶部构建快速且强大的MPI系统。

计算能力:
网络:
冷却:
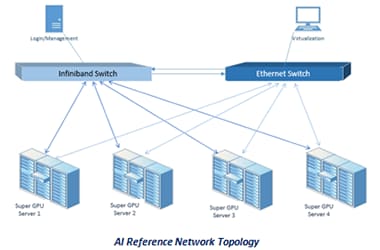
随着HPC和AI交织越来越多,高精度计算的未来越来越明显。通过AI的深度学习功能,可以在一些最复杂的HPC域中获得有趣且全新的发现!为了满足将HPC与AI相结合的应用程序不断增长的计算能力需求,Supermicro提供了具有高可扩展性和可配置性的多功能集群解决方案。

计算能力:
解决方案SKU:
网络:
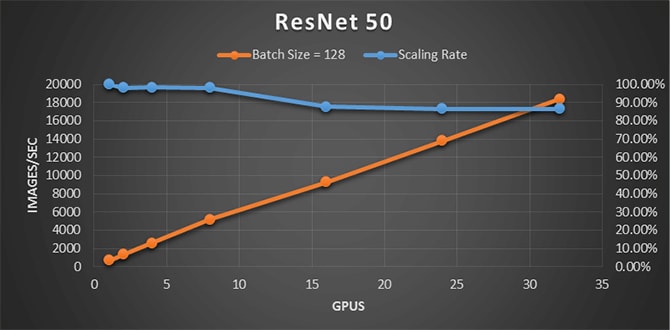
Supermicro HPC团队在基准AI性能方面取得了显着成果。Supermicro AI设备的性能已经使用各种广泛使用的深度学习算法进行了评估,例如VGG,Inception V3,ResNet 50等。大多数时候,我们的设备的性能优于当前可用的AI集群的流行和当前选择。市场。例如,以下TensorFlow基准测试(使用ResNet 50)显示每秒成功处理近18000个图像。
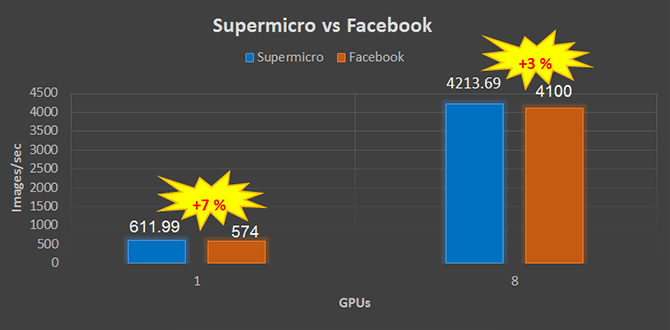
我们的HPC团队还将Supermicro AI设备的性能与AI硬件提供商的其他领先市场领导者进行了比较,结果令人印象深刻且更好。例如,以下Caffe2基准测试(使用ResNet 50)表明,与Facebook相比,Supermicro AI集群解决方案每秒可处理更多图像:
Ansys软件套件为工程师提供了一个标准化平台,可以高效地设计和运行仿真。Supermicro与Ansys合作,提供专为Ansys应用量身定制的硬件,以便从Ansys产品中获得最佳性能。使用Supermicro的Ansys解决方案,设计,运行和查看模拟结果之间的周转时间大大缩短,这将使工程团队能够加快开发过程。
Supermicro Ansys解决方案旨在有效地利用Ansys软件套件,并提供一些不同的软件包,从小型和经济高效到具有足够马力的大型集群。Supermicro Ansys解决方案包含经过精心挑选的高性能组件,即使在最剧烈的模拟中也能最大限度地减少瓶颈,以确保最终用户无论在何种情况下都能充分利用每个硬件组件。硬件功能包括:
| 小集群 | 大型集群(1U服务器) | 大型集群(2U服务器) | ||
|---|---|---|---|---|
| 模型 | ||||
| 计算节点 | 高达10 | 最多32个 | 最多32个 | |
外形 (每个节点) |
服务器 | 1U Ultra | 1U Ultra | 2U TwinPro |
| CPU | 2x SKL 6134 3.2 GHz | 2x SKL 6134 3.2 GHz | 2x SKL 6134 3.2 GHz | |
| 内存 | 256 GB | 256 GB | 256 GB | |
| 硬盘 | 1.6 TB SSD | 1.6 TB SSD | 1.6 TB SSD | |
| 总核心 | 最多160 | 最多512 | 最多512 | |
| 总内存 | 高达2560 GB | 高达8192 GB | 高达8192 GB | |
| 总存储量 | 高达16 TB | 高达52.1 TB | 高达51.2 TB | |
| 主节点 | 1 | 2 | 2 | |
服务器 |
服务器 | 1U Ultra | 1U Ultra | 1U Ultra |
| CPU | 2x SK 6134 3.2 GHz | 2x SK 6134 3.2 GHz | 2x SK 6134 3.2 GHz | |
| 内存 | 256GB | 256GB | 256GB | |
| 硬盘 | 1.6TB SSD | 1.6TB SSD | 2TB SSD | |
| 显卡 | NVIDIA Quadro GP100 16GB GDDR5 | |||
| 端口 | 24端口10GbE | Omni-Path或EDR或FDR | ||
| IPMI 52端口 | ||||
| 高度 | 14U | 42U | ||
| PDU | 1x2U 30A | 2x 50A 208三相计量PDU | ||
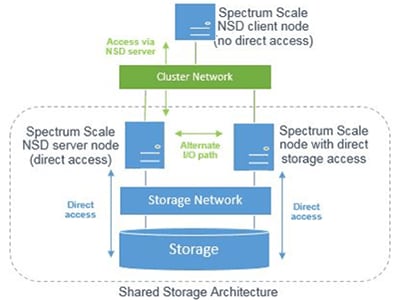
Spectrum Scale为数据中心提供了灵活的存储平台,允许最终用户以极高的速度访问大量数据。Scale的性能秘诀是一个分层存储层次结构,它将常用数据优先排序到最快的存储层,同时将其余数据保存在更具成本效益的存储设备上,以便按需访问。IBM Spectrum Scale智能存储规则允许用户根据需要自定义其硬件的使用。
Supermicro为HPC应用提供基于Specturm Scale的解决方案。
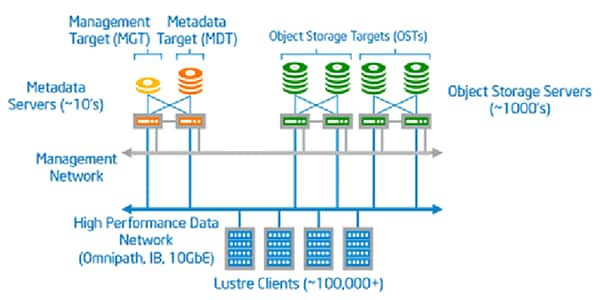
Lustre是一个并行文件系统,可为数PB的存储提供HPC工作负载所需的速度。Lustre Solution允许数千个客户端按需访问存储设备。通过将服务器上的元数据和数据分离,可以实现此解决方案,这意味着客户可以根据它们将运行的工作负载来设计和定制其集群。Lustre已经在世界上一些最大的数据中心进行了时间测试,事实上,Lustre目前支持地球上100强超级计算机的75%。Supermicro与英特尔和BGI配对,为BGI实验室提供了一个8Gb / s速度的Lustre系统!
FatTwin?
TwinPro2?
GPU服务器
超级服务器
SuperBlade刀片?
英特尔的Omni-Path技术是下一代网络。凭借低延迟和高吞吐量,英特尔Omni-Path交换机提供了两全其美的优势。我们建议超微英特尔?全路径任何HPC客户是谁关心他们的网络性能是一个问题。
Mellanox的InfiniBand交换机是HPC高速互连的另一个绝佳选择。HPC在网络中需要低延迟和高吞吐量,这正是InfiniBand提供的。
Supermicro HPC服务器平台提供内置的Mellanox EDR或FDR适配器或可选的SIOM。
HPC解决方案只能表现最差的链接。因此,从高速缓存一致性和检查指向资源管理,重要的是每个硬件组件在最佳状态下执行以确保整个群集满足期望。Supermicro开发了一个独特的测试套件,从组件级别开始构建。该测试套件允许我们的工程师捕获并解决可能发现的任何性能差异,并进行适当的更改以确保最终集群的整体质量。
Supermicro测试套件旨在从端到端覆盖整个产品,这意味着它包含细粒度的细节以及集群级测试。这个过程减少了时间和精力,使我们的产品能够到达客户现场,随时可以即插即用。
Supermicro Benchmarking团队将向您展示我们的产品!为了让我们的客户能够衡量我们产品的原始功率,我们提供一系列细粒度,每个组件的基础,以及集群级基准测试。我们团队生成的基准数据帮助我们的最终客户了解他们将使用的产品的全部潜力,并深入了解其群集的功能。我们的基准测试流程是根据客户用于运营其集群的软件和工作负载定制设计的。该过程进一步确保集群在解压缩并插入后即可立即运行。
下面的列表包含我们的标准基准,但我们也很乐意做其他人。如果您有您感兴趣的基准但未在列表中看到,请随时与我们联系以获取查询。
| 集群软件堆栈 | ||||||
|---|---|---|---|---|---|---|
| 深度学习环境 | 构架 | Caffe,Caffe2,Caffe-MPI,Chainer,微软CNTK,Keras,MXNet,Tensorflow,Theano,PyTorch | ||||
| 图书馆 | cnDNN,NCCL,cuBLAS | |||||
| 用户访问权限 | NVIDIA DIGITS | |||||
| 编程环境 | 开发和性能工具 | 英特尔Parallel Studio XS群集版 | PGI集群开发套件 | GNU工具链 | NVIDIA CUDA | |
| 科学与传播图书馆 | 英特尔MPI | MVAPICH2,MVAPICH | IBM Spectrum LSF | 打开MPI | ||
| 调试器 | 英特尔IDB | PGI PGDBG | GNU GDB | |||
| 调度程序,文件系统和管理 | 资源管理/ |
自适应计算机摩押,Maui TORQUE | SLURM | Altair PBS专业版 | IBM Spectrum LSF | 网格引擎 |
| 文件系统 | 光泽 | NFS | GPFS | 本地(ext3,ext4,XFS) | ||
| 集群管理 | Beowulf,xCat,OpenHPC,Rocks,用于HPC的Bright Cluster Manager,包括对NVIDIA数据中心GPU Manager的支持 | |||||
| 操作系统和驱动程序 | 驱动因素和网络管理。 | 加速器软件堆栈和驱动器 | OFED,OPA | |||
| 操作系统 | Linux(RHEL,CentOS,SUSE Enterprise,Ubuntu等) | |||||
| 集群测试套件 | ||
|---|---|---|
| 集群级别测试 | WRF,NAMD | |
| 基准测试 | HPL,HPCC,HPCG,Igatherv,DGEMM,PTrans,FFT | |
| 并行存储测试 | IOR,MDTest | |
| 系统组件测试 | 中央处理器 | 压力,CPU压力 |
| 内存 | STREAM,SAT | |
| 网络 | Netperf,Iperf,OSU基准 | |
| 硬盘 | FIO,IOZone,DD,hdparm | |